はじめに:データを入れないと何も始まらない!
Snowflakeを使い始めるとき、最初にぶつかる壁が「どうやってデータを入れるの?」という問題です。どれだけ強力なクラウドDWHでも、中身のデータが空っぽでは何も分析できませんよね。
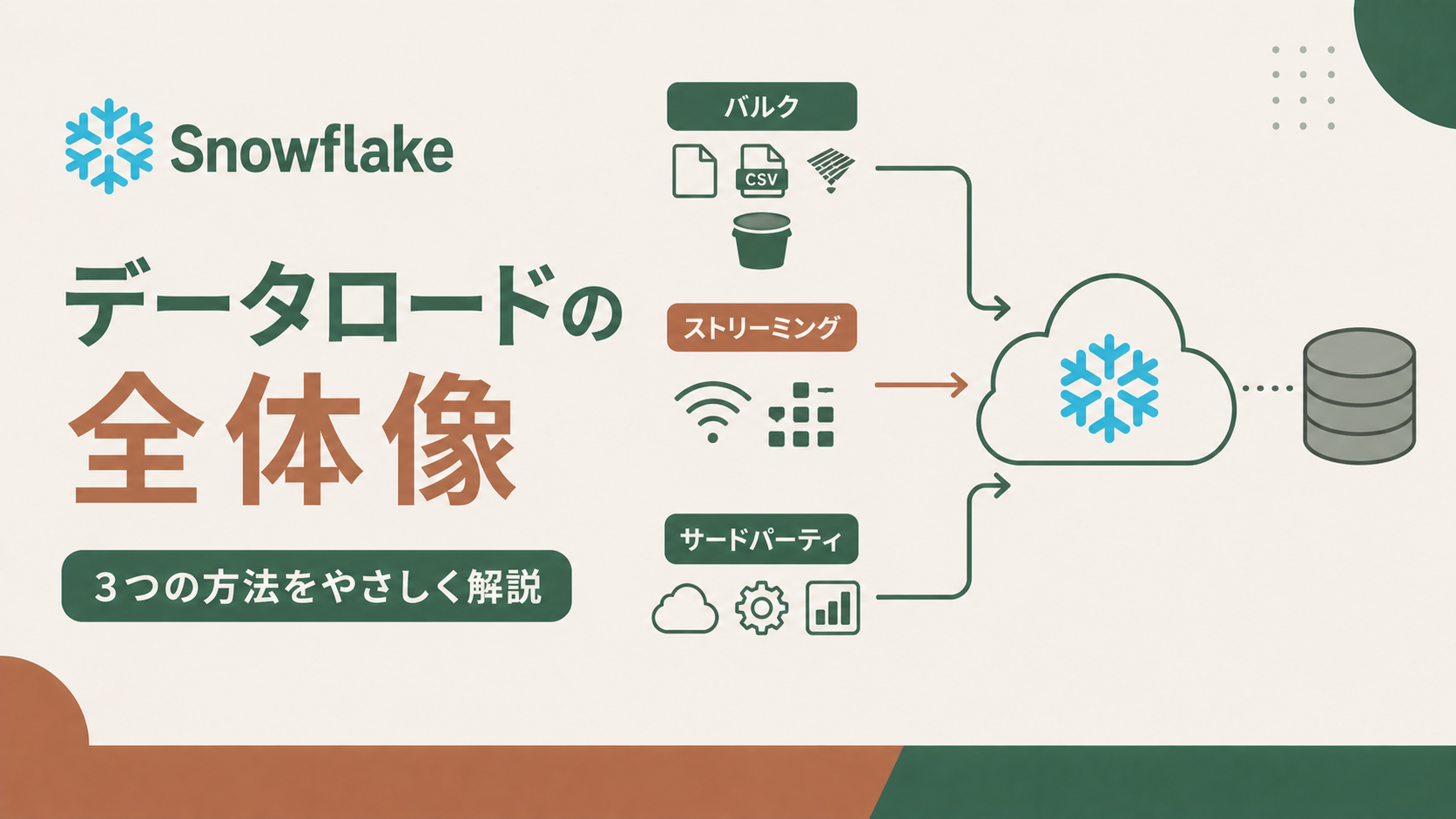
この記事では、Snowflake公式が示すデータロードの3つの方式(バルクロード・ストリーミング・サードパーティ連携)の全体像を、初心者の方向けにやさしく整理します。違いを押さえておくと、自分のユースケースにピッタリな方法をスムーズに選べるようになりますよ!
方式①:バルクロード(まとめてドカンと入れる)
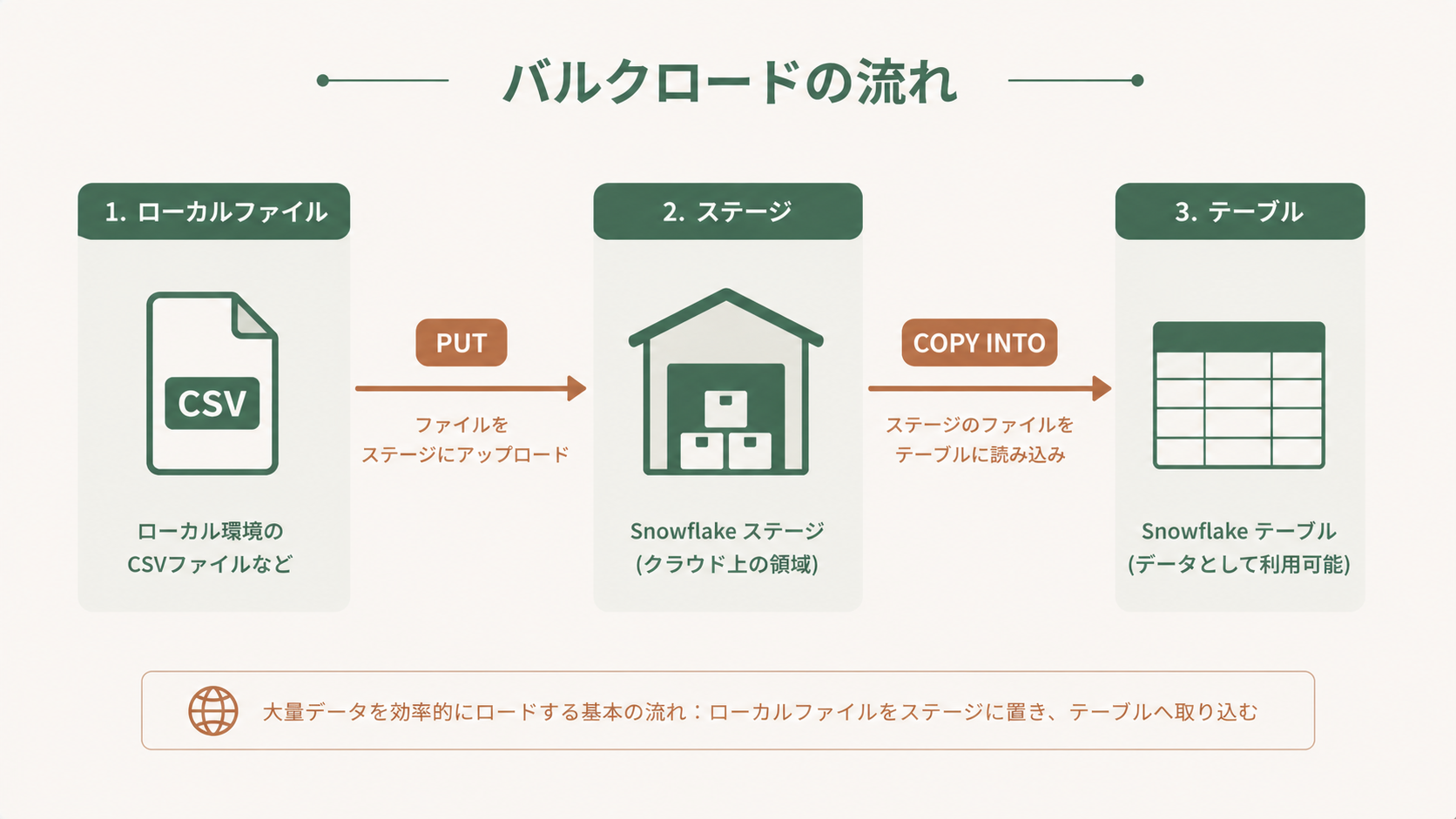
バルクロードは「ファイルにまとまったデータを、一気にテーブルに流し込む」やり方です。前日分のCSVを毎晩深夜にロードする…といったバッチ処理にピッタリ。仕組みはシンプルで、いったんステージ(Snowflake内外のファイル置き場)にファイルを置き、COPY INTO コマンドでテーブルへ取り込みます。
-- ローカルファイルを内部ステージへアップロード(SnowSQL)
PUT file://./sales_2026_04.csv @%sales;
-- ステージからテーブルへ一括ロード
COPY INTO sales
FROM @%sales
FILE_FORMAT = (TYPE = CSV SKIP_HEADER = 1);ローカルからのアップロードには SnowSQLのPUTコマンド が便利ですし、Snowsightの画面 からドラッグ&ドロップでロードすることも可能です。ロード処理には仮想ウェアハウスが使われるので、サイズによって速度が変わる点も覚えておきましょう。
方式②:ストリーミング(届いたそばから取り込む)
「翌朝まで待てない、できるだけリアルタイムに分析したい!」という時に使うのがストリーミングロードです。代表選手は次の2つ。
- Snowpipe:S3などにファイルが置かれた瞬間を検知し、自動で
COPY INTOを実行してくれるサービス。数十秒〜数分の遅延でデータが反映されます。 - Snowpipe Streaming:ファイルを介さず、行単位で直接テーブルに書き込むAPI。秒以下のレイテンシを実現できます。
IoTセンサー・アプリログ・クリックストリームなど、データが絶え間なく発生するケースに最適です。サーバーレスで動くため、ウェアハウスを起動しっぱなしにする必要がないのも嬉しいポイント。
方式③:サードパーティツール(コネクタにお任せ)
3つ目は、FivetranやAirbyte、Talend、Matillion といったETL/ELTツールに取り込みを任せる方法です。SaaS(Salesforceなど)や業務DBから、ノーコードでSnowflakeへデータを同期できます。
「コネクタを選ぶ → 認証情報を入れる → 同期スケジュールを設定」のステップだけで済むので、SQLを書かずに本格的なデータ基盤を構築可能。Snowflake公式の Partner Connect から数クリックで連携を開始できます。
3つの方式の使い分け早見表
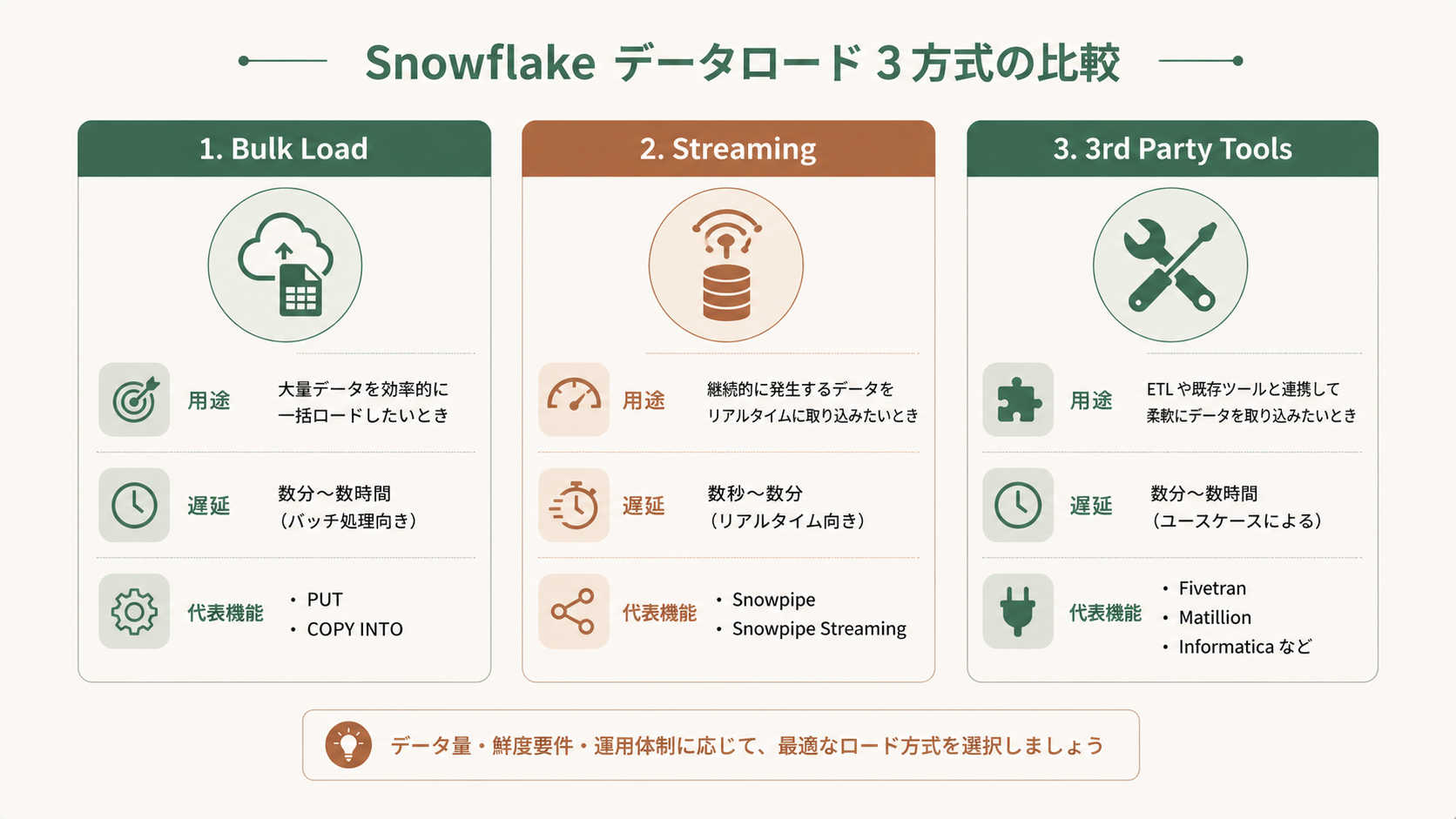
- バルク:夜間バッチ・初期ロード →
COPY INTO - ストリーミング:準リアルタイム分析 → Snowpipe / Snowpipe Streaming
- サードパーティ:SaaS・業務DB連携 → Fivetran等のコネクタ
まとめ
Snowflakeへのデータロードは「どれくらい新鮮なデータが必要か」と「データの出元(ファイル/API/SaaS)」で選ぶのが基本です。まずはバルクロードで テーブル階層 にデータを入れてみて、ニーズに合わせてSnowpipeやサードパーティ連携にステップアップしていくのがおすすめ。3層アーキテクチャ のおかげで、どの方式を選んでもストレージとコンピュートが切り離されて効率よく動いてくれますよ!
参考リンク
関連記事
- SnowSQLのインストールと基本的な使い方を初心者向けに解説 – PUTコマンドでローカルファイルをステージへアップロードする方法を詳しく解説。
- Snowsightの画面構成と基本操作を初心者向けにやさしく解説 – Web UIからのデータロード操作の前提知識として。
- Snowflakeのデータベース・スキーマ・テーブル階層を初心者向けに解説 – ロード先の構造をしっかり押さえたい方へ。
- Snowflakeウェアハウスとは?サイズと使い分けを初心者向けに解説 – バルクロードの速度はウェアハウスサイズに直結します。
- Snowflakeの3層アーキテクチャを初心者向けにやさしく解説 – データロードの裏側を支えるアーキテクチャの全体像。